Blogpost vom 10. Dezember 2019
KI in der Landwirtschaft Teil II: Deep Learning

Künstliche Intelligenz muss trainiert werden. Wie ein KI-Algorithmus lernt, mithilfe von Deep Learning und Computer Vision Kulturpflanzen von Unkräutern zu unterscheiden – auch, wenn die Datenlage schlecht ist – erklärt uns KI-Expertin Laura Fink in diesem zweiten Teil von Train as you fight. Den ersten Teil lesen Sie hier.
Künstliche Intelligenz erobert nun zunehmend unsere Felder. Die Landwirtschaft erforscht intelligente Technologien wie Deep Learning und Computer Vision, um Erträge zu steigern und exakte Erntezeitpunkte zu bestimmen. So können Kosten gespart und Prozesse optimiert werden – indem analysiert und berechnet wird, ob und wie viel gewässert werden muss oder welche Krankheiten sich auf dem Feld ausbreiten. Auch das frühzeitige Erkennen und Entfernen von Unkräutern kann junge Pflanzen in ihrem Wachstum stärken.
In unserem Computer Vision Showcase zeigen wir, wie Deep Learning dabei helfen kann, Pflanzenarten voneinander zu unterscheiden.
Bilddaten: Grundlage für Deep Learning & Computer Vision
Für diesen Showcase haben wir öffentlich verfügbare Bilddaten der Computer Vision and Biosystems Signal Processing Forschungsgruppe der Universität Aarhus verwendet. Die Daten beinhalten Bilder von 12 verschiedenen Wild- und Kulturpflanzen, die häufig auf dänischen Feldern zu finden sind.
Nicht nur die Menge und die Qualität der Daten trägt maßgeblich zum erfolgreichen Einsatz von KI bei. Beim Sammeln der Daten müssen wir auch beachten, dass sich keine unbewussten Fehlerquellen einschleichen.
Im ersten Teil von KI in der Landwirtschaft konnten wir Ihnen bereits zeigen, dass die Bilddaten der Forschungsgruppe einen so genannten Target Leakage in sich tragen: Anhand der Größe der Steine im Hintergrund der Pflanzen lässt sich bereits berechnen, wie wahrscheinlich welche Pflanzenart zu finden ist. Mit dem Einsatz von Tools wie LIME oder SHAP zur Erklärbarkeit von Machine-Learning-Vorhersagen haben wir Ihnen demonstriert, wie wir solche Fehler aufspüren und Data Science Workflows debuggen können.

Feature Extraction: Konzentration auf das Wesentliche
Wie können wir verhindern, dass der KI-Algorithmus die Größe der Steine zur Hilfe nimmt, um Pflanzenarten voneinander zu unterscheiden? Indem wir Menschen dafür sorgen, dass sich der lernende Algorithmus auf das Wesentliche konzentriert.
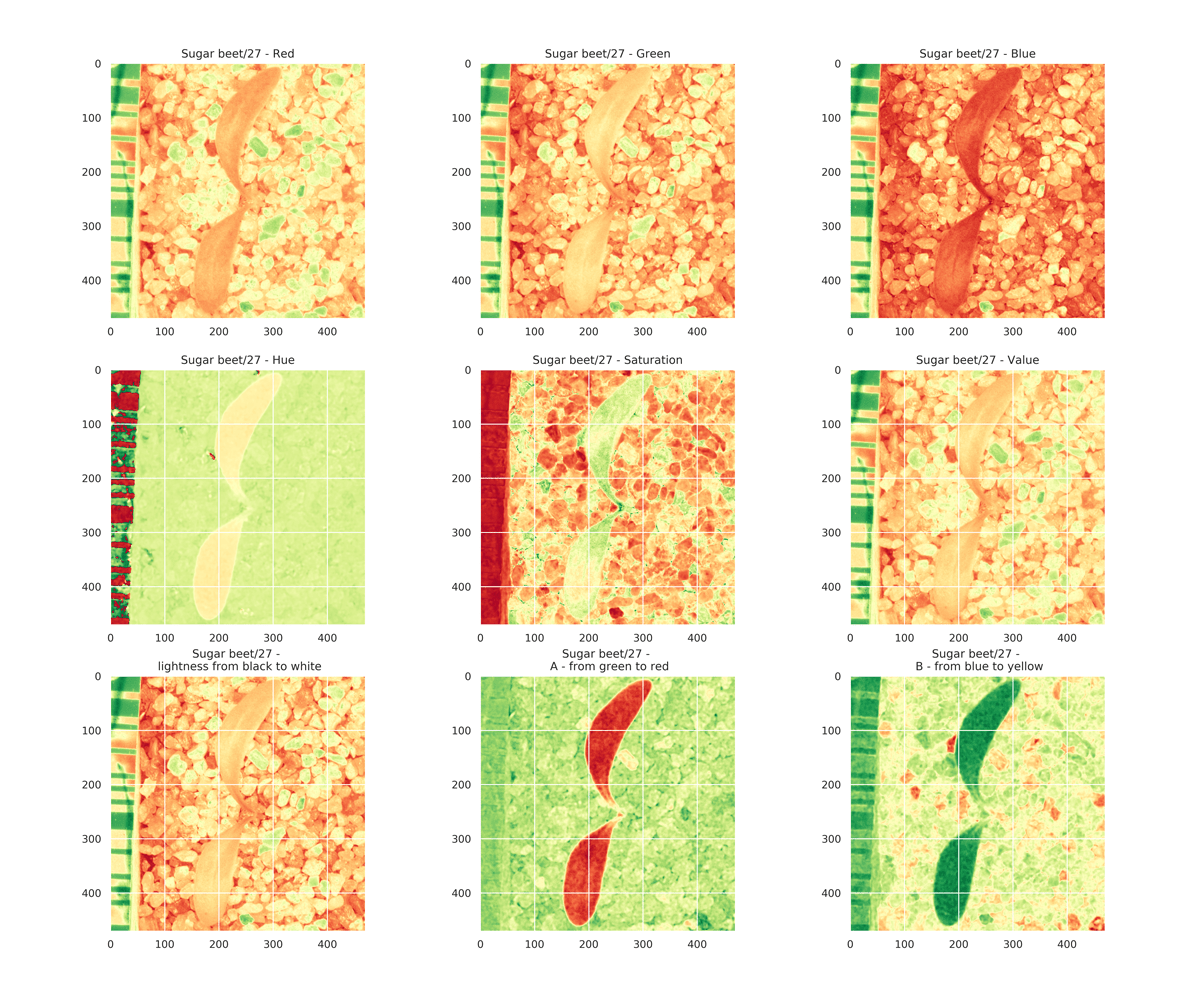
Dafür müssen die Steine aus dem Hintergrund entfernt werden. Aber natürlich nicht händisch, sondern digital. Um das zu schaffen, nutzen wir den Umstand, dass die drei Werte, die in einem Pixel gespeichert werden, vom gewählten Farbraum abhängen. Wechseln wir nämlich vom üblichen RGB-Raum (Rot-Grün-Blau) zum LAB-Raum (Helligkeit, Rot-Grün, Blau-Gelb), dann heben sich die Pflanzen im Rot-Grün-Kanal deutlich von den Steinen ab und wir können die Steine mit einem einfachen Schwellwert-Verfahren aus dem Bild entfernen!
Transfer Learning: Den KI-Algorithmus umschulen
Beim Deep Learning werden Künstliche Neuronale Netze mit vielen Neuronenschichten verwendet – daher der Begriffsbestandteil „Deep“. Aufgrund ihrer hohen Komplexität und Flexibilität benötigen sie jedoch sehr große Datenmengen, um erfolgreich zu lernen. Wer wie in unserem Fall nur wenige Bilddaten zur Verfügung hat, greift deshalb besser auf einen Algorithmus zurück, der zum Lösen einer ähnlichen Aufgabe bereits trainiert wurde.
Dieses populäre Verfahren nennt sich Transfer Learning und beruht darauf, dass die ersten Neuronenschichten in einem Künstlichen Neuronalen Netz Eigenschaften aus den Bildern extrahieren, die von Bedeutung sein könnten: Ecken und Kanten, Texturen und einfache Muster. Erst in späteren Neuronenschichten werden dann Objekte oder Teilobjekte extrahiert, die zum Lösen einer spezifischen Aufgabe nötig sind – in unserem Fall die Pflanzenbestimmung.
Entfernt mal also die letzten Schichten eines bereits trainierten Künstlichen Neuronalen Netzes, passt sie der eigenen Aufgabe entsprechend an und trainiert nur sie allein, so spart man viel Zeit und benötigt deutlich weniger Daten.
Der Gemeine Windhalm ist keine Salz-Binse
Bis auf zwei Ausnahmen können alle Pflanzenarten mit einer sehr hohen Güte von etwa 99 % voneinander unterschieden werden. Einzig allein der Gemeine Windhalm wird in einigen Wachstumsphasen falsch als Salz-Binse klassifiziert. Betrachtet man die dazugehörigen Bilder, ist es jedoch selbst dem menschlichen Auge kaum möglich, die Unterschiede zu erkennen. Um das Problem zu lösen, wären eine bessere Bildqualität und weitere Pflanzenmerkmale nötig.
Fazit
Im ersten Teil von KI in der Landwirtschaft haben wir Ihnen gezeigt, wie Sie mit Tools zur Erklärbarkeit von Machine-Learning-Ergebnissen so genannte unerkannte Fehler beim Sammeln und Verarbeiten Ihrer Daten verhindern können. In diesem zweiten Teil konnten wir Ihnen zeigen, wie Sie mithilfe von Feature Extraction und Transfer Learning auch angesichts kleiner Datenmengen große Erfolge erzielen können. Deep Learning und Computer Vision sind also auch bei einer suboptimalen Datenlage durchaus sinnvolle Technologien.
Die vollständige Analyse hier: https://www.kaggle.com/allunia/computer-vision-with-seedlings
Copyright-Informationen hier: https://vision.eng.au.dk/plant-seedlings-dataset/
© 2014 Mads Dyrmann, Peter Christiansen, University of Southern Denmark, and Aarhus University
The images and annotations are distributed under the Creative Commons BY-SA license.
If you use this dataset in your research or elsewhere, please cite/reference the following paper:
PAPER: A Public Image Database for Benchmark of Plant Seedling Classification Algorithms


